

개인화 추천, 어떻게 하는데? (3) - Transformer 완전 정복!

안녕하세요! Z.Ai 팀의 ML 엔지니어 Simon입니다.
지난 글에서 ChatGPT의 기본 모델이 되는 Transformer의 핵심인 Attention에 대해 설명을 드렸는데요! 이번 글은 Transformer 정복을 위한 마지막 글로, 전반적인 Transformer 속 Encoder의 구조, 그리고 그것이 어떻게 추천 시스템에 적용되고 있는지에 대한 설명을 드리고자 합니다.
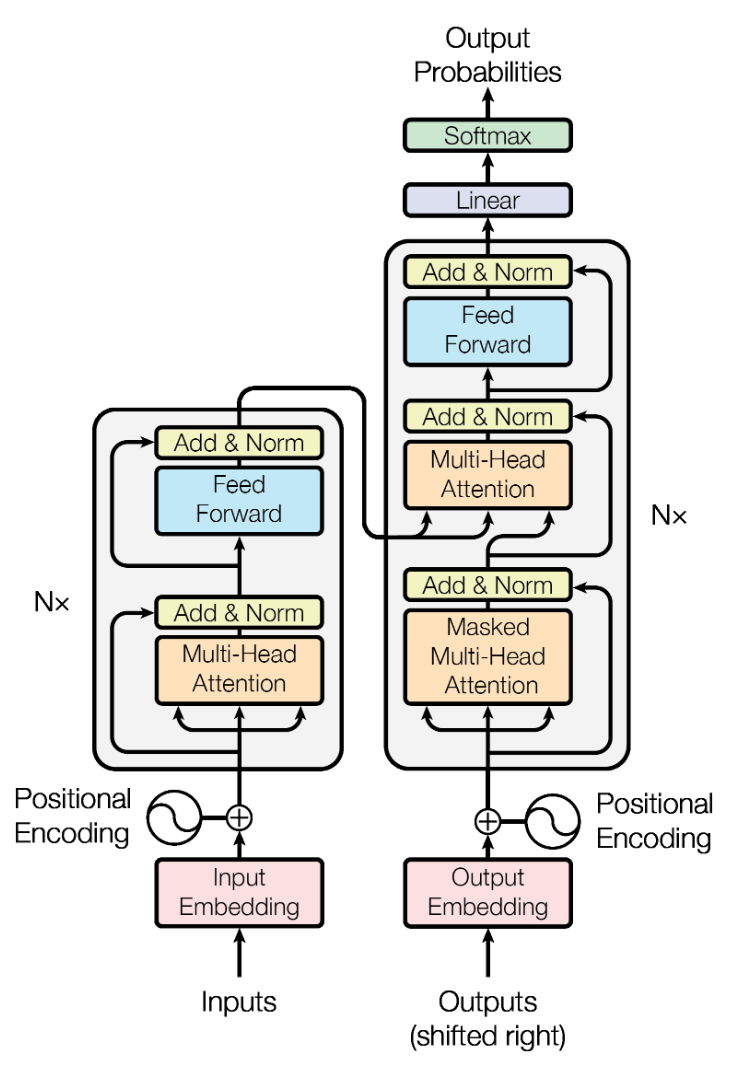
출처 : Attention is All You Need (Ashish Vaswani, 2017)
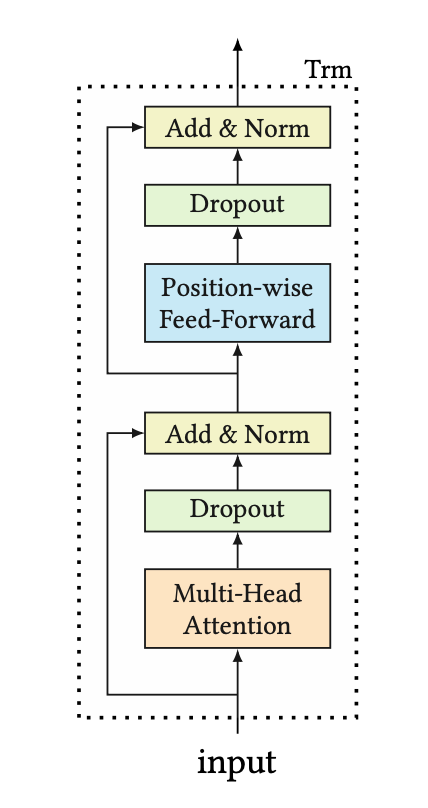
출처: BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer (Fei Sun, 2019)
Transformer의 Encoder는 크게 Multi-Head Attention Layer와 Point-wise Feed-Forward Layer 두 부분으로 구성이 되어 있고, Transformer 연산을 위해 Input을 Vector로 변환시켜주는 Embedding Layer가 존재합니다.
추천 시스템에서 Transformer는 사용자의 행동 데이터의 패턴을 파악하기 위해 사용됩니다. 즉, 사용자가 과거 상호작용을 진행한 상품들을 시간 순으로 정렬하여 Transformer의 Input으로 사용하며, 이를 라고 정의하겠습니다.
Embedding Layer는 주어진 상품들 사이의 관계를 파악하기 위해 이를 Vector로 바꾸어 주는 Layer이며, 동작 방식은 다음과 같습니다.
- 훈련 시작 전 데이터 베이스에 존재하는 모든 상품들의 수만큼 Vector를 임의의 값으로 초기화시켜 Item Embedding Matrix를 정의합니다.
- 초기화된 Item Embedding Matrix에서 Input으로 주어진 상품들에 해당하는 Vector들을 쌓아 S를 하나의 Embedding Matrix로 표현합니다.
즉, Input S가 Embedding Layer를 지나면 2차원 행렬로써 Input이 표현되게 됩니다.
추가적으로 Sequential Recommendation을 위해서는 해당 상품들이 몇 번째 순서로 상호작용 되었는지에 대한 정보가 필요합니다. 이를 위해 Positional Embedding Matrix 을 정의하여 행동데이터를 표현하는 행렬에 더해 상품들이 어떤 순서로 상호작용되었는지에 대한 정보를 반영해줍니다.
이렇게 도출된 최종적인 행렬을 소비자 행동행렬 이라고 정의하겠습니다. 이때, Embedding Layer에서 사용되는 Item Embedding Matrix와 Positional Embedding Matrix 모두 Gradient Descent가 적용되는 학습가능한 파라미터입니다.
Multi-Head Attention Layer는 Embedding Layer를 통해 추출된 행동행렬의 패턴을 파악하는데 사용됩니다. 이때, Multi-Head Attention Layer는 지난 시간 설명드렸던 Scaled Dot-Product Attention을 통해 동작합니다. Scaled Dot-Product Attention에 대해 간략하게 요약하면 Query와 Key 사이의 관계를 내적을 통해 Attention Distribution을 구한 뒤 이를 Value에 곱해 Weighted Sum을 통해 Value들을 Aggregation하는 Attention 기법입니다.
[Self-Attention]
Transformer의 Multi-Head Attention은 Query, Key, Value가 모두 Input으로 같은 Self-Attention 기법을 이용합니다. 즉, Input으로 주어진 행동행렬 H에 나타나는 패턴을 자기 자신을 통해 판단하는 것으로 이해할 수 있습니다. 이를 그림으로 표현하면 다음과 같습니다.
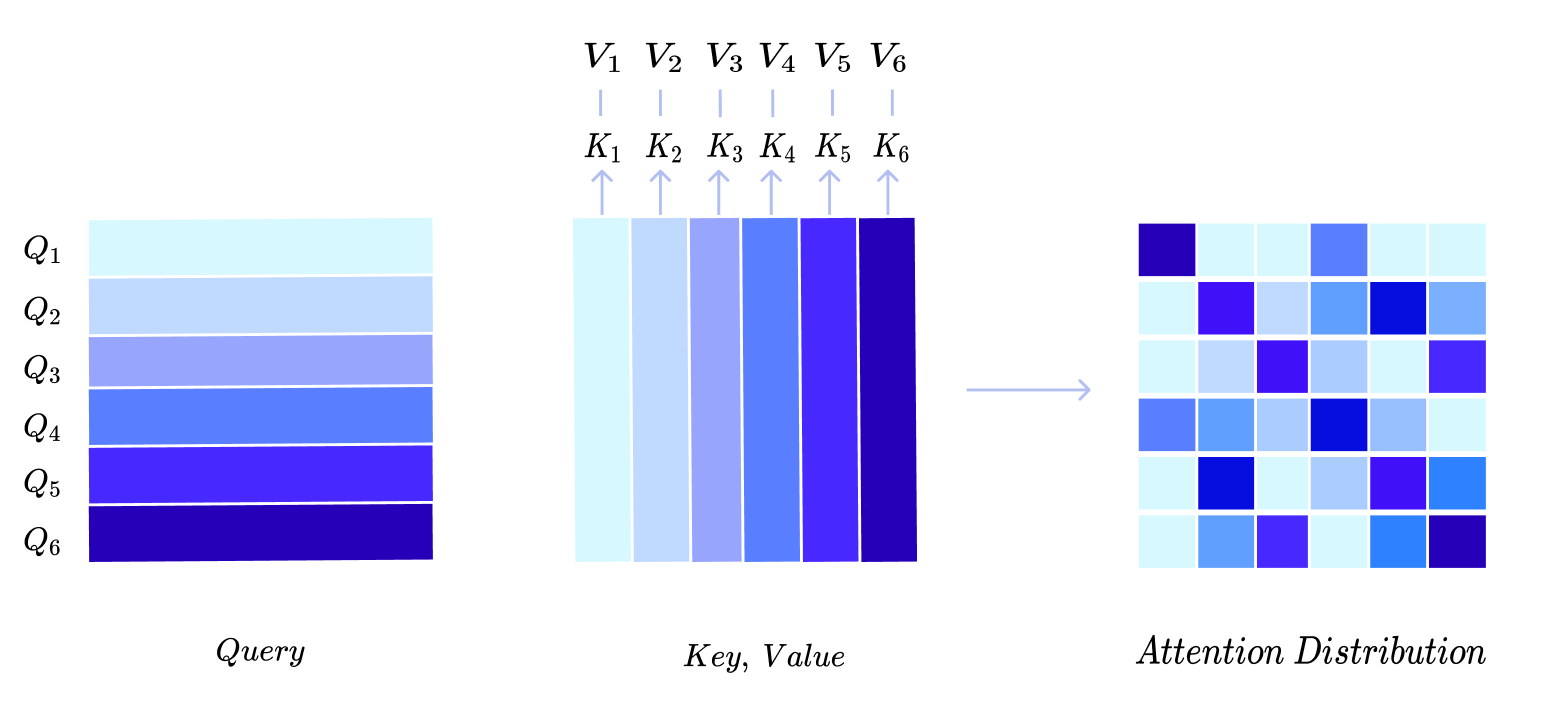
Attention Distribution Matrix의 (i, j) 번째 값의 의미는 i번째 상품과 j번째 상품의 유사도를 내적을 통해 측정한 값이 됩니다. Query와 Key가 같은 Vector이므로 Attention Distribution Matrix는 Symmetric Matrix가 됩니다. 또한 Attention Distribution의 대각 요소들은 자기 자신과의 유사도이므로 매우 큰 값을 가지게 됩니다.
위 그림에서 색이 진할 수록 유사도가 높게 측정되었다고 가정한다면 첫 번째 행에서 4번째 열에 있는 값이 다른 값에 비해 그 값이 크므로 첫 번째 상품과 네번째 상품은 유사도가 높은 상품이라고 판단할 수 있습니다.
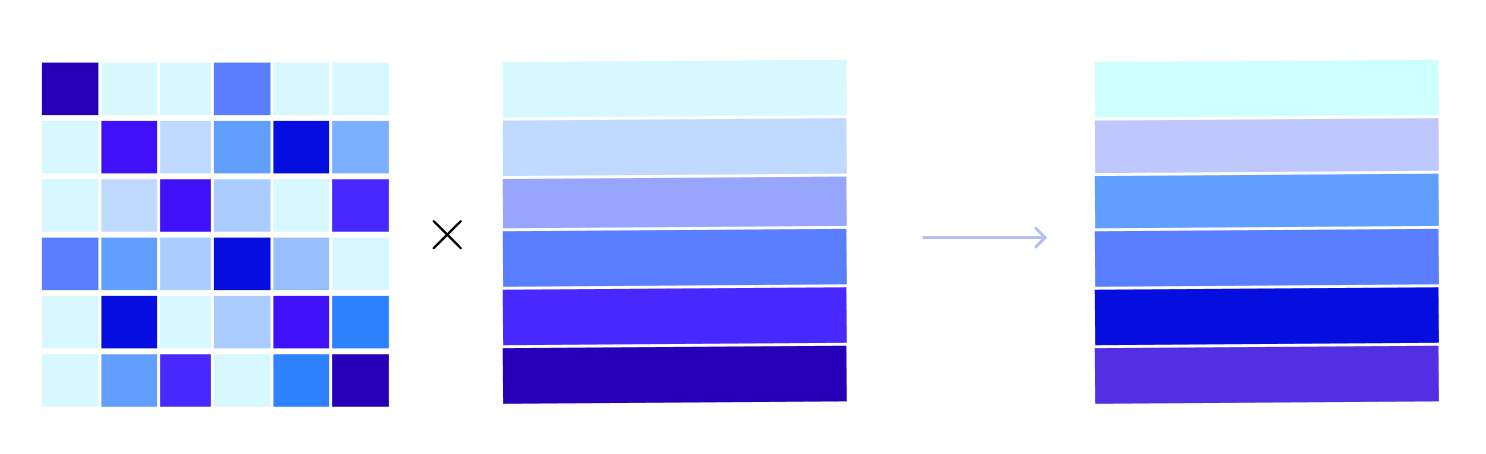
다음으로 Attention Distribution과 Input을 행렬곱하여 다른 Sequence의 정보가 합쳐진 새로운 Matrix를 구할 수 있습니다. 위 그림을 기준으로 Output Matrix의 첫번째 행벡터의 경우 첫번째 상품과 네번째 상품이 강하게 반영되어 있는 Vector가 형성되었다고 이해할 수 있습니다.
[Multi-Head Attention]
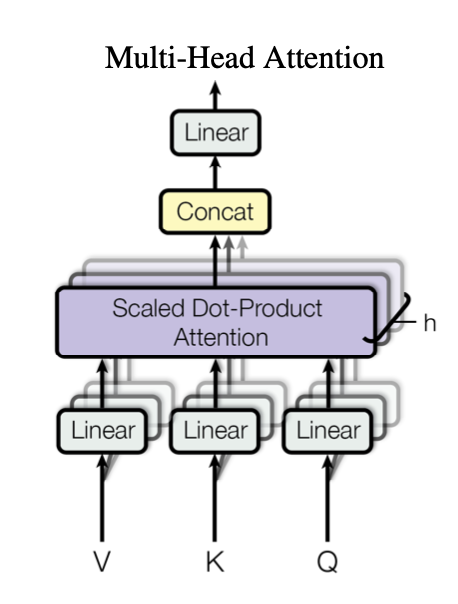
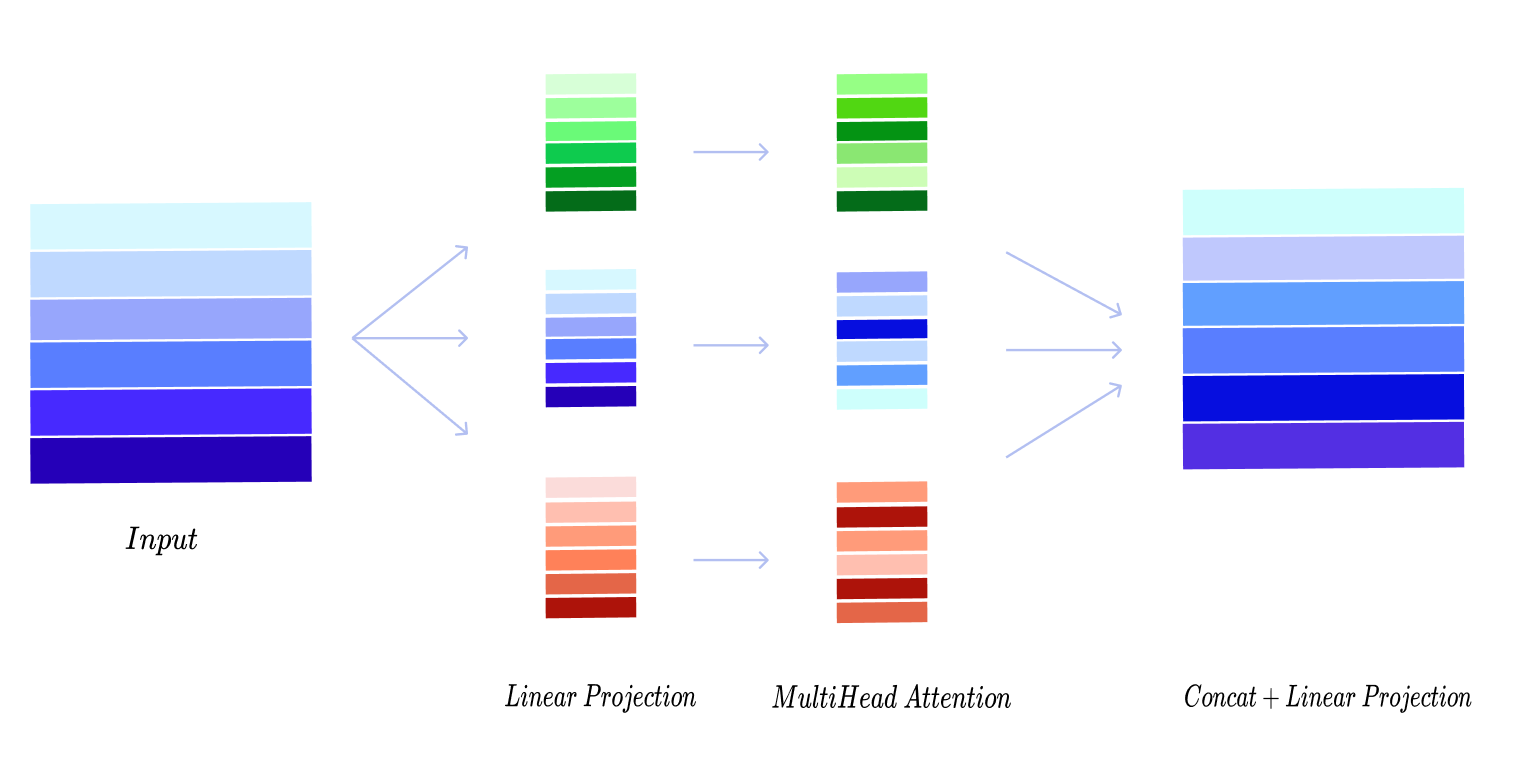
Multi-Head Attention은 위 Self-Attention을 한번만 진행한 것이 아닌 동시에 여러번 진행한 것입니다. 즉, Attention을 여러 관점에서 다각도로 시행하여 특정 관점에 치우치지 않게 Attention을 진행하였다고 풀어 설명할 수 있습니다. Multi-Head Attention 연산의 수행과정은 다음과 같습니다.
- 우선 Self-Attention을 진행할 Head의 개수 h를 정한 뒤 Input으로 들어온 행동행렬 를 개의 다른 공간에서 바라볼 수 있게 Linear Projection을 시키는 과정이 필요합니다. 이 과정은 주로 Input Vector의 차원이 이고, 가 Head의 개수라면 의 차원으로 Projection합니다. i번째 Head에 대한 Linear Projection을 수식으로 표현하면 다음과 같습니다.
- 그 다음으로 각 Head에서 Scaled Dot-Product Attention을 진행합니다. 이는 위에서 서술한 Self-Attention 방식으로 계산됩니다. 각 Head에서 계산된 Attention Output은 $n \times d/h$ 의 차원을 가지는 Matrix가 됩니다.
- 각 Head에서 계산된 Output을 이어 붙여(Concatenation) 최종 Output을 형성한 뒤 해당 Output을 다시 한번 Linear Projection하여 각 Output들을 적절히 배합합니다.
Multi-Head 연산은 반복문을 돌 필요 없이 행렬 연산으로 한번에 가능하기 때문에 연산상 효율성 역시 보장되며 Single-Head일 때보다 더 안정적이고 우수한 성능을 보여줍니다.
Multi-Head Attention이 Input 사이에 존재하는 관계를 잘 포착하였다하더라도 Linear 연산만을 진행하기 때문에 Model의 Desicion Boundary 형성에 한계가 존재합니다. 때문에 Non-Linear 연산을 진행하여 모델에 유연성을 부여하는 Layer가 Point-Wise Feed-Forward Layer입니다.
Non-Linear 연산에는 미분가능한 함수들인 Tanh, Sigmoid, ReLU, GeLU 등이 사용가능하며, Gradient Vanishing 때문에 ReLU계열 Activation 함수들이 주로 사용됩니다.
Transformer Layer는 Multi-Head Attention과 Point-wise Feed-Forward Layer로 구성되어 있고, Transformer Layer를 여러개 쌓아 순차 정보를 더 잘 파악할 수 있게 합니다. 다만 이렇게 모델이 복잡해지게 될 경우 훈련시간이 오래 걸리고, 과적합, Gradient Vanishing 문제 등이 발생하기 때문에 이를 완화하기 위해 Residual Connection, Layer Normalization, Dropout과 같은 여러 장치들이 곳곳에 존재합니다. 본 글에서는 각 장치들을 간단하게만 설명하겠습니다.
[Residual Connection]
Residual Connection은 Low-Layer의 결과를 다음 Layer에 전달하여 Low-Layer의 유의미한 정보가 마지막 Layer까지 전파될 수 있게 하기 위한 장치입니다. 또한 역전파 단계에서 Gradient가 소실되는 것 또한 방지할 수 있습니다.
[Layer Normalization]
Layer Normalization 기법은 Input을 Feature 단위로 정규화시켜주는 기법으로 모델은 안정적이고, 더욱 빠르게 학습시키기 위해 사용됩니다. 만일 Embedding Vector가 Input이라면 Dimension을 축으로 평균과 표준편차를 구해 정규화가 이루어집니다. 이와 비슷한 기법으노 Batch Normalization이 있으며, Batch Normalization은 Batch 축으로 평균과 표준편차를 구해 정규화를 시킵니다.
[Dropout]
Dropout은 훈련 단계마다 Neural Network에서 임의로 일부 Node와의 연결을 끊어 특정 Node들에 편향되어 학습되는 것을 막아 과적합을 방지하는 Regularization 기법입니다.
이렇게 Transformer Encoder의 내부 구조에 대한 설명이 마무리되었는데요, Z.Ai 머신러닝 팀은Transformer를 기반으로 양질의 큐레이션을 제공하기 위해 다양한 모델을 만들고 있습니다. 이번 글에서는 해당 모델들의 기본이 되는 BERT4REC에 대한 설명을 드리고 글을 마무리하려 합니다.
BERT는 Google에서 Transformer의 Encoder를 이용하여 주어진 문장의 Context를 추출하기 위해 제안된 모델입니다. 추천 시스템에서는 2019년에 BERT의 구조를 차용하여 주어진 행동행렬의 Context를 추출하는 모델이 제안되었습니다.
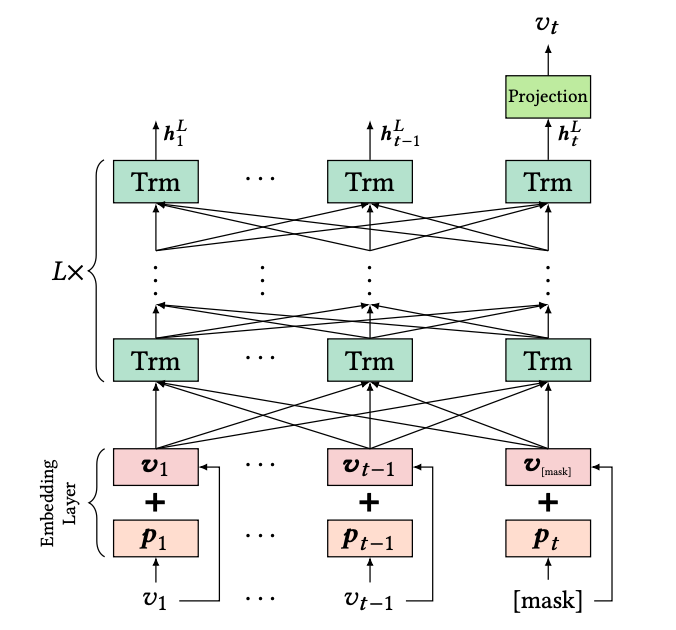
BERT4REC은 BERT에서 제안된 Masked Language Model의 방식을 차용합니다. Masked Language Model은 주어진 문장에서 일부 토큰들을 Mask처리하여 해당 자리에 들어갈 토큰을 맞추는 방식으로 학습을 진행합니다. 이와 마찬가지로 BERT4REC은 주어진 과거 행동 데이터에서 일부 상품들을 Mask처리하여 해당 자리에 들어갈 상품을 맞추는 방식으로 학습이 진행됩니다. 실제 추천을 진행할 때는 사용자의 과거 행동 데이터 마지막에 Mask를 붙여 해당 자리에 들어갈 상품이 무엇인지 예측하는 방향으로 추천이 진행됩니다.
조금 더 구체적으로 그 과정을 살펴보겠습니다.
Input으로는 과거 사용자가 상호작용을 진행한 상품들이 시간 순으로 정렬되어 들어옵니다. 그리고 해당 Input을 구성하는 상품들을 임의로 선택하여 Mask 토큰으로 바꾸어 버립니다.
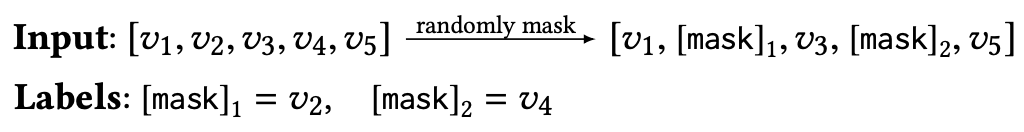
이렇게 만들어진 Masked Input을 Transformer Layer에 넣어 연산을 진행하는데요, 그 과정을 도식화하면 다음과 같이 표현할 수 있습니다.
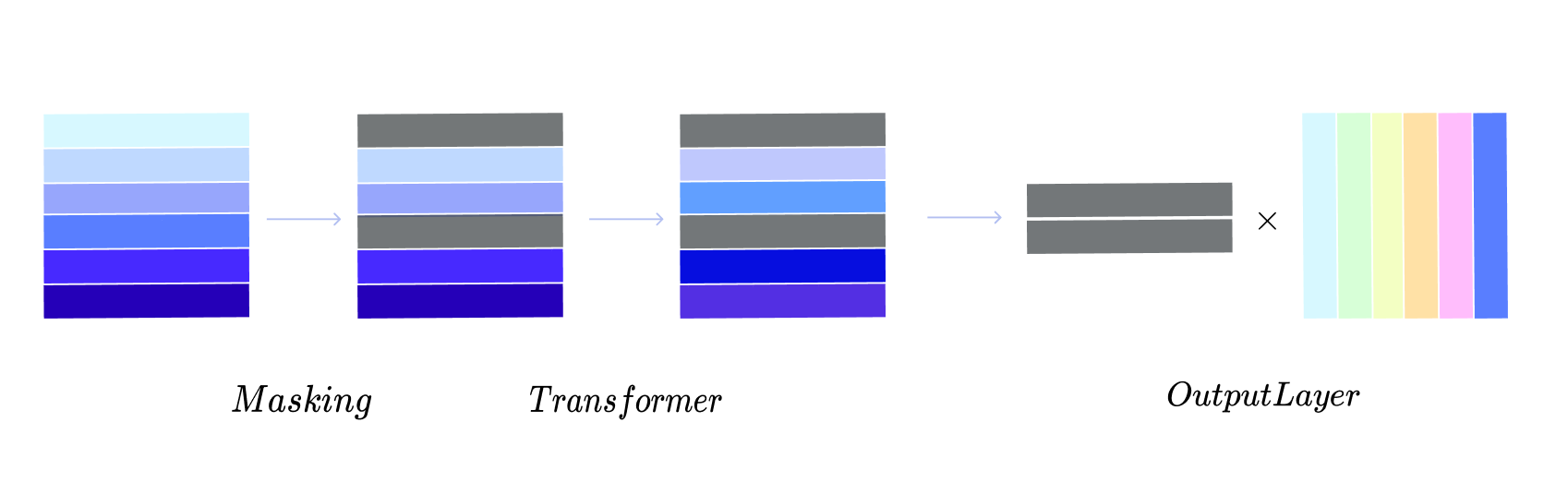
Mask가 씌워진 Token의 경우 Transformer Layer를 지나고 나면 다른 행동 데이터의 정보가 반영된 Vector가 형성되며, 최종 Output Layer에서는 해당 Vector와 추천 후보가 되는 Item Embedding Matrix와 내적을 통해 유사도를 구하고 Softmax 연산을 통해 각 상품이 해당 위치에 존재할 확률을 구하게 됩니다. 이후 모델은 Label 상품의 확률값이 높아지도록 학습이 이루어집니다. 이를 수식으로 표현하면 다음과 같습니다.
: Masked Item의 Transformer Output
: Item Embedding Matrix
BERT4REC은 현재 Z.Ai가 실제 서빙에 사용하는 모델들의 Baseline으로써 사용자의 행동 정보를 추출하는데 사용되고 있습니다. 하지만 BERT4REC만으로는 큐레이션 단계에서 발생하는 Business 문제들을 해결하기에 역부족인 경우가 많습니다. 가령 Transformer 계열의 모델들은 상품들의 상대적인 위치관계를 모델에 반영하기 때문에 주기성과 같은 Temporal 정보가 반영되기 어렵고, 사용자가 좋아요를 누르는 등 명확한 선호표현을 하였을 때의 정보를 반영하기도 무리가 있습니다. 때문에 여러 방법론을 결합하여 Transformer만으로는 해결할 수 없는 문제들을 해결하고 있는데요, 앞으로의 블로그 글에서는 Z.Ai가 양질의 큐레이션을 위해 어떤 모델을 만들고 있는지 설명드리도록 하겠습니다. 😊
[참고문헌]
Attention is All You Need, Ashish Vaswani, 2017
Self-Attentive Sequential Recommendation, WC Kang, 2018
BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer, Fei Sun, 2019

 자이의 개인화 추천으로 구매전환율 및 매출의 상승을 경험해 보세요!
자이의 개인화 추천으로 구매전환율 및 매출의 상승을 경험해 보세요!