

개인화 추천 어떻게 하는데? - (2) Transformer - Attention
chatGPT에 사용된 Transformer 모델, 정체가 뭘까?

안녕하세요 Z.Ai팀의 ML 엔지니어 Simon입니다.
최근 유명세를 타고 있는 ChatGPT에 사용된 모델인 GPT가 Transformer의 한 종류라는 사실을 알고 계셨나요? 🤭 GPT는 Generative Pre-trained Transformer의 줄임말로 Google에서 공개한 Transformer를 생성형 AI에 맞게 내부 구조를 변경한 뒤 학습한 모델입니다. Transformer는 NLP(자연어처리)영역에서 제안된 알고리즘이지만 추천시스템에도 활발히 적용되고 있는 알고리즘이기도 합니다. 이번 글에서는 실제 추천 모델에 적용하고 있는 딥러닝 알고리즘 중 하나인 Transformer에 대해 설명을 드리고자 합니다!
Transformer는 기본적으로 어떠한 순서 정보를 가지고 있는 순차 데이터(Sequential Data)에 나타나는 패턴을 학습하기 위해 고안된 Attention 기반의 알고리즘입니다. 쉽게 풀어내면 순차적으로 나열된 데이터(토큰)사이의 관계를 파악하여 어떤 데이터에 어느 정도의 가중치를 부여해야하는지를 학습하는 알고리즘이라고 설명할 수 있습니다. 그렇다면 Transformer를 추천 시스템의 관점에서 어떻게 사용할 수 있을까요? 🤔
추천 시스템에서 사용자의 행동데이터는 사용자가 과거에 상호작용을 진행한 상품들이 시간 순(chronological order)으로 나열된 데이터로 표현됩니다. 즉, 사용자 행동데이터를 구성하는 상품들이 하나의 토큰이라고 생각할 수 있습니다. 그리고 이 사용자가 어떤 상품을 어떤 순서로 상호작용하였는지를 파악하면 사용자의 행동패턴을 추출할 수 있을 것입니다. 이 과정에서 Transformer가 사용될 수 있습니다.
Transformer는 사용자가 과거에 상호작용한 상품들을 벡터로 표현한 뒤 이 벡터들을 합쳐 최종적인 사용자의 행동패턴을 특정 벡터로 표현하는데 사용됩니다. 이 과정을 Aggregation 혹은 Pooling이라고 이야기합니다. 사실 벡터를 합치는데는 여러 방식이 존재합니다. 대표적인 방법으로는 주어진 벡터들 중 가장 중요하게 동작하는 벡터를 선택하는 방식(Max Pooling)과 이 벡터들을 평균하여 하나의 벡터로 표현하는 방식(Average Pooling)이 존재합니다. 하지만 Max Pooling은 하나의 상품을 제외한 나머지 상품 정보들은 무시된다는 단점이 있고, Average Pooling은 상품들을 같은 가중치로 단순히 산술평균을 하기 때문에 사용자가 유심있게 본 상품의 정보를 표현할 수 없다는 단점이 존재합니다. Transformer는 이들과 달리 사용자의 행동 데이터를 잘 표현할 수 있는 상품들에 더 많은 가중치를 주면서도 나머지 상품들에 대한 정보 손실이 발생하지 않게 Aggregation하는 방식이라고 할 수 있습니다. 이 과정에서 Attention이 핵심 역할을 담당합니다.
Attention은 딥러닝의 대표적인 알고리즘인 Neural Network가 주어진 데이터들 사이의 관계를 학습하기에 제한적이라는 한계를 극복하기 위해 고안된 알고리즘입니다. 데이터들 사이의 관계는 다양하게 정의될 수 있지만 딥러닝에서는 통상적으로 데이터들이 얼마나 유사한가로 정의합니다. 즉, 데이터를 표현하는 벡터들의 내적을 통해 그 관계를 파악하는 것이죠. 구체적으로 Attention이 어떻게 동작하는지 살펴보겠습니다.
Attention의 궁극적인 목표는 주어진 벡터들의 가중합을 구하는 것입니다. 이때 가중치가 곱해지는 대상이 되는 벡터들을 Value라고 정의합니다. 추천 시스템의 관점에서는 사용자들이 과거에 상호작용을 진행한 상품들이 됩니다. 그리고 Value 벡터의 가중치들은 해당 Value를 잘 표현할 수 있는 데이터와 유사성을 측정할 대상이 되는 데이터의 내적으로 구해지게 됩니다. 전자를 Key, 후자를 Query라고 정의합니다. 많은 경우 Value와 Key는 같은 값을 가지게 됩니다. 예를 들어 어떤 사용자의 행동 데이터들을 Aggregation할 때, 특정 상품 A과 유사한 상품에 더 큰 가중치를 주고 싶다면 Query는 상품 A의 벡터가 되고, Key와 Value는 사용자의 과거 상호작용하였던 상품들의 벡터가 됩니다. 이를 그림으로 표현하면 다음과 같습니다.
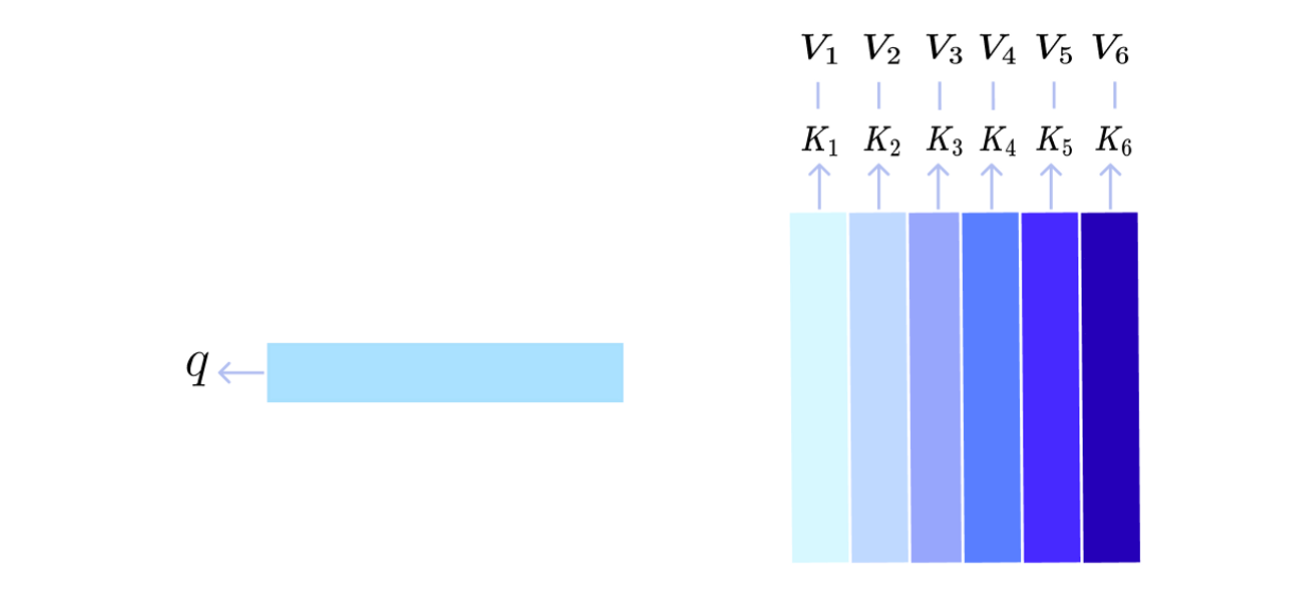
이때 는 상품 A의 벡터, 와 는 i번째에 사용자가 상호작용한 상품의 벡터가 됩니다. 이들을 서로 내적하면 하나의 상수값(Scalar)으로 유사도가 측정됩니다. Query 벡터와 i번째 상품벡터인 의 유사도를 라고 정의하겠습니다.
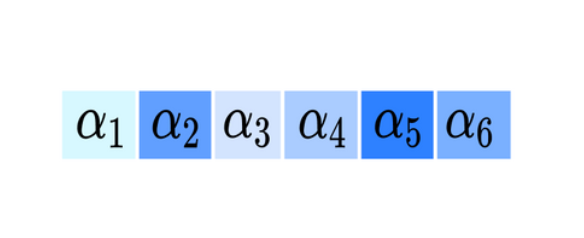
내적 연산을 마치게 되면 위 그림과 같이 Query로 주어진 상품벡터와 사용자가 과거 상호작용을 진행한 상품들사이의 유사도가 담긴 벡터가 만들어지게 됩니다. 이는 그 값이 클 수록 서로 유사한 상품이었음을 의미합니다.
다음으로 이 유사도값들의 합이 1이 되도록 Normalize과정을 진행합니다. 이때 Softmax 연산이 적용되며, 이 과정 이후 각 유사도의 값은 확률값으로 해석될 수 있습니다. 이를 Attention Distribution이라고 이야기합니다. 이후 Attention Distribution의 값을 Value의 각 벡터에 곱한 뒤 이들을 더해 Value 벡터들을 Aggregate한 새로운 벡터를 생성하게 됩니다. 추천 시스템의 관점에서는 상품 A와의 유사도한 상품에 더 많은 가중치를 주어 사용자의 행동패턴을 추출한 벡터를 의미하게 됩니다.
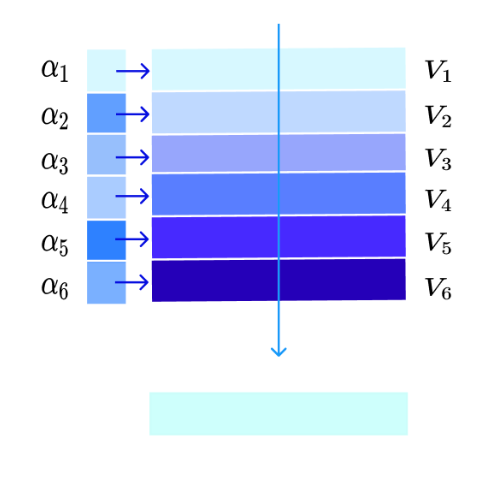
즉, Attention 알고리즘은 Query와 Key의 관계를 포착할 수 있는 연산을 진행하여 Attention Distribution을 구한 뒤 Key와 맵핑이 되어 있는 Value에 해당 가중치를 곱하는 방식으로 계산됩니다. 이때 Query나 Key의 차원으로 scaling을 진행하여 더욱 안정적인 연산을 진행합니다. 이렇게 내적(Dot Product)을 이용하여 관계를 측정하고, Scaling을 진행하는 Attention을 Scaled Dot-Product Attention이라고 이야기합니다. 이를 식으로 표현하면 다음과 같습니다.
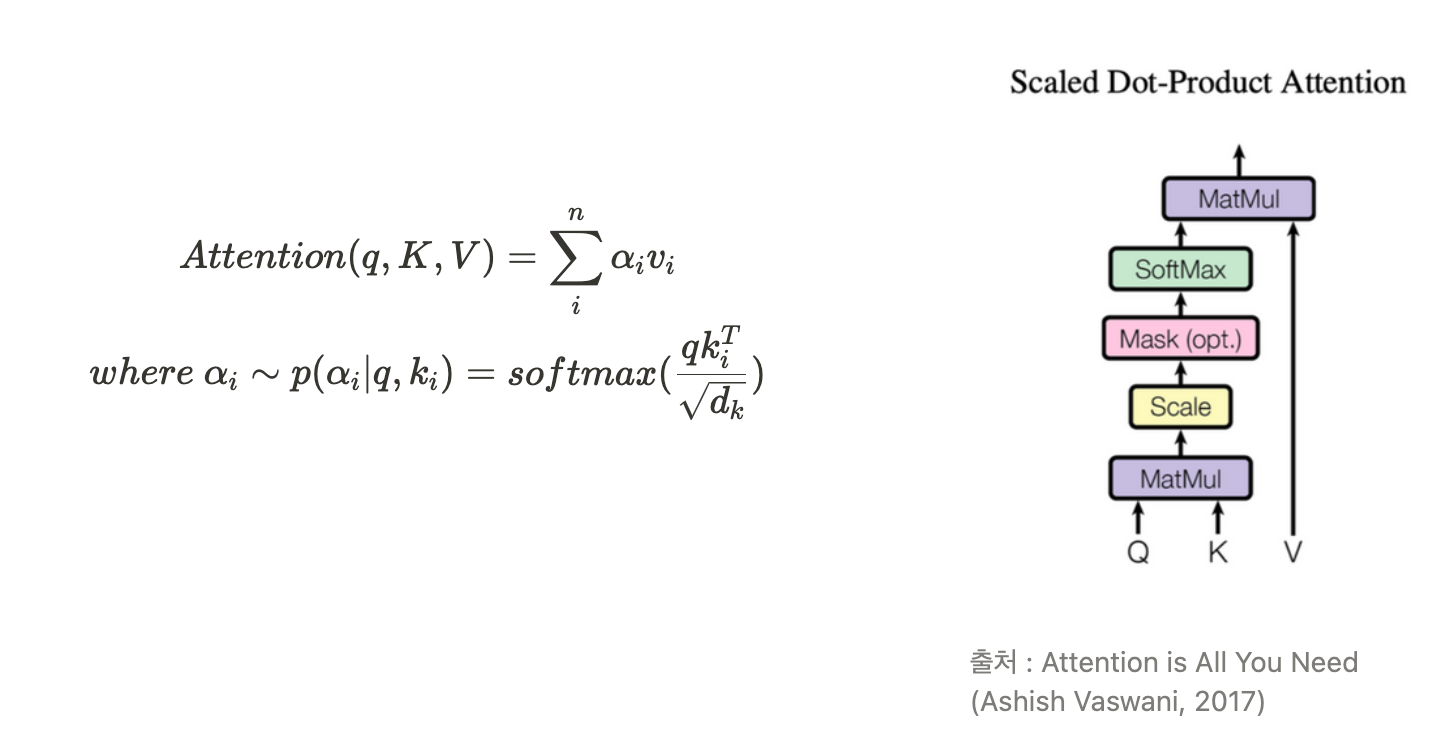
Attention 알고리즘은 Max Pooling처럼 Hard하게 하나의 벡터를 선택하는 것이 아니기 때문에 soft-selection 방식이라고 불리기도 합니다.
Transformer는 이러한 Attention을 기반으로 하여 순차 데이터에서 나타나는 일종의 패턴을 학습하는데 특화된 알고리즘으로 다양한 모델의 기반이 되고 있습니다. Transformer를 처음 제안한 논문에서는 자연어처리의 번역과 같이 입력된 데이터를 다른 도메인의 데이터로 변형하는 Sequence-to-Sequence 모델을 위해 Encoder, Decoder 구조를 채택하고 있지만 추천 시스템에서는 다른 도메인의 값으로 출력하는 것이 아닌 주어진 Input의 Context를 파악하는데 그 목적을 두고 있기 때문에 Encoder만을 이용하여 모델링을 진행합니다.
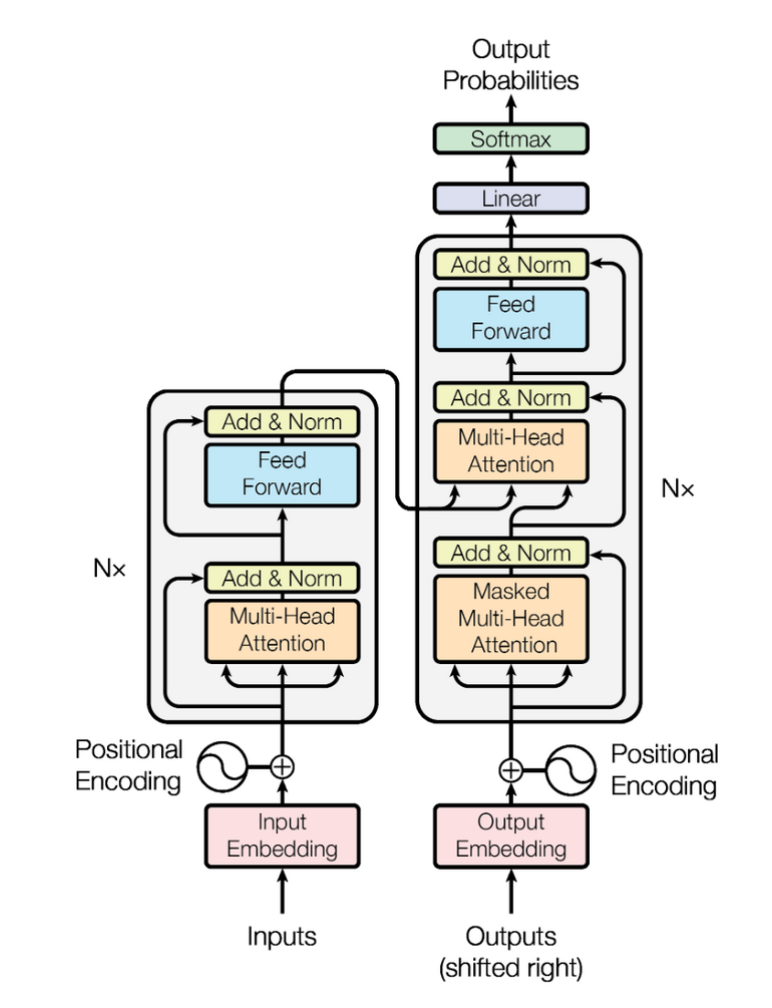
Transformer의 전체 구조는 다음과 같고, 좌측이 Encoder, 우측이 Decoder 연산과정을 도식화한 것입니다.
이때, Encoder 부분만 따로 구분하여 도식화하면 다음과 같습니다.
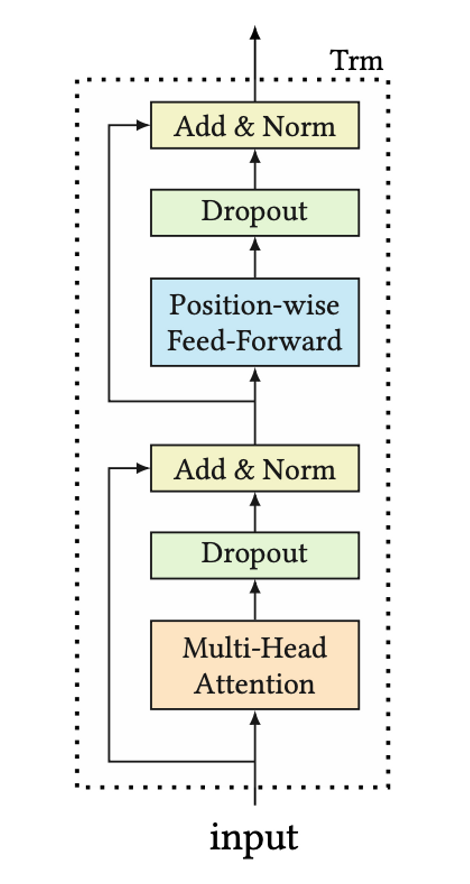
Transformer의 Encoder는 크게 Multi-Head Attention Layer와 Position-wise Feed-Forward Layer로 구성되어있으며, Multi-Head Attention이 주어진 Input의 관계를 파악하는데 중요한 역할을 합니다. 이 Multi-Head Attention에서 위에 설명한 Scaled Dot-Product 방식이 사용됩니다. 다음 글에서는 Transformer 내부 연산인 Multi-Head Attention과 Position-wise Feed-Forward에 대해 자세히 설명하고, 추천 시스템에서는 어떤 방식으로 학습을 진행하는지 더욱 깊숙히 알아보겠습니다! 🙂
[참고문헌]
Structured Attention Network, Yoon Kim, 2017
Attention is All You Need, Ashish Vaswani, 2017
BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer, Fei Sun, 2019

 자이의 개인화 추천으로 구매전환율 및 매출의 상승을 경험해 보세요!
자이의 개인화 추천으로 구매전환율 및 매출의 상승을 경험해 보세요!