

Z.Ai 개인화 추천, 어떻게 하는데? (1) 임베딩과 순차 데이터 모델

안녕하세요 Z.Ai팀의 ML 엔지니어 Simon입니다. 😊
지난번 게시물에서 자이가 왜 개인화 추천 솔루션을 더 많은 기업에게 제공하고자 하는지에 대한 간략한 설명을 드렸다면, 오늘은 Z.Ai의 머신러닝 팀이 고성능의 개인화 추천을 제공하기 위해 어떤 시도들을 하고 있는지 말씀드리고자 합니다.
Z.Ai 팀은 양질의 개인화 큐레이션을 제공하기 위해 사용자를 잘 이해할 수 있는 머신러닝 모델을 만들고 있습니다. 그리고 큐레이션의 관점에서 사용자를 이해하기 위해서는 사용자에 대한 단순한 정보 뿐만 아니라, 과거 사용자가 주로 어떤 상품들과 상호작용을 하였는 지 등의 행동 데이터에서 유의미한 정보를 잘 추출해낼 수 있는 모델이 필요하다고 생각하였습니다. 즉, 행동 데이터에서 사용자가 상호작용하는 상품들이 어떤 특징을 가지고 있는 가에 대한 상품 특성 정보(Attribute Information)와 사용자가 상품과 어떤 패턴으로 상호작용하는 가에 대한 문맥적 정보(Contextual Information)를 잘 학습할 수 있는 딥러닝 모델이 필요하였습니다. 이번 글에서는 Z.Ai가 위 두 정보들을 어떻게 활용하여 모델을 설계하고 있는 지에 대한 전반적인 설명을 드리도록 하겠습니다.
우선 상품 특성 정보를 딥러닝 모델이 학습하기 위해서는 이 정보들을 수치화하여 수학적 공간에 표현할 수 있어야합니다. 이때 임베딩 기법이 통상적으로 사용됩니다. 임베딩은 한 개체가 가지는 여러가지 특징을 수치로 표현하여 수학적인 공간에 표현하는 기법을 이야기합니다. 구체적으로는 각 상품들이 가지는 특징들을 벡터화하여 벡터공간(Vector Space)으로 주로 맵핑을 시킵니다. 각 정보들을 벡터공간에 맵핑시키는 이유는 벡터공간에서는 벡터의 거리와 두 벡터 사이의 각도 등 여러 binary operation을 통해 두 벡터의 유사성을 쉽게 측정할 수 있기 때문입니다.
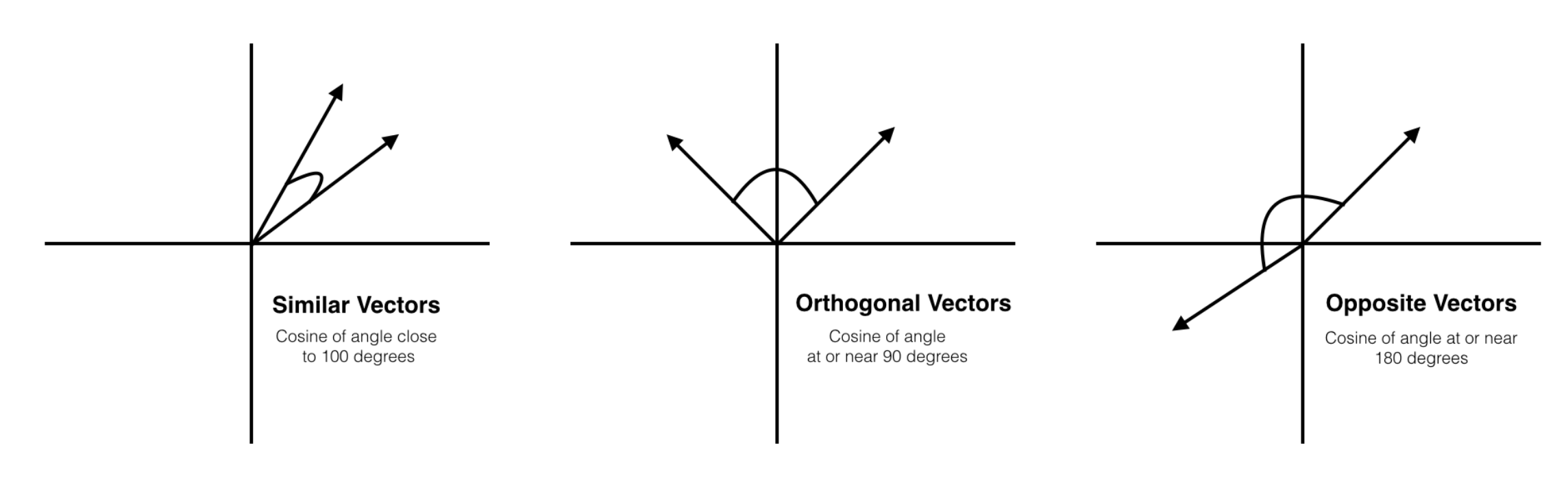
임베딩을 통해 벡터공간에 맵핑하는 정보는 비단 상품 특성 정보만이 아닙니다. 사용자의 행동패턴을 통해 파악한 문맥적 정보 역시 벡터화하여 상품 특성 정보와 같은 벡터공간에 맵핑을 하게 됩니다. 이후 최종적인 추천은 사용자의 문맥적 정보에 대한 벡터와 유사한 상품 벡터들을 추출하여 해당 상품들을 추천합니다.
추천 시스템의 최종 목표는 비슷한 특징을 가진 상품벡터를 비슷한 곳에 위치시키는 것입니다. 하지만 이때 비슷한 특성이란 데이터마다 다릅니다. 커머스에서는 카테고리 혹은 브랜드가 해당 특성을 표현할 수도 있고, 콘텐츠에서는 장르나 제작자가 상품의 특성을 표현할 수도 있습니다. 그리고 추천 시스템은 사용자 행동데이터를 기반으로 상품이 가지는 어떤 정보들을 추출할 것이며, 어떻게 비슷한 곳에 위치시킬 것인 지를 데이터를 통해 학습을 진행합니다. 그럼 추천 시스템은 어떻게 데이터에서 유의미한 정보들만을 추출하여 벡터공간에 맵핑을 시키는 것일까요?
사용자의 행동데이터는 과거 사용자들이 어떤 상품들과 상호작용을 진행했는지에 대한 상품들의 순서쌍으로 표현이 가능합니다. 즉, 행동데이터를 일정한 순서를 가지고 발생하는 순차 데이터로서 파악할 수 있습니다. 이에 딥러닝에서 활발히 연구되고 있는 순차 데이터 모델을 차용할 수 있습니다. 순차 데이터 모델의 핵심은 순차적으로 나열된 토큰들을 어떻게 하나의 벡터로 표현할지를 학습하는 것입니다. 이때 추천 시스템에서 토큰은 사용자가 상호작용한 상품들로 정의할 수 있습니다. 추천 시스템은 사용자 행동 데이터을 구성하는 상품들을 어떻게 벡터로 임베딩시킬 지와 순차적으로 나열된 상품들에 대한 벡터를 어떻게 하나의 벡터로 합쳐 사용자의 행동 패턴을 표현할 지 학습하게 됩니다.
대표적으로 사용되는 모델은 Attention 알고리즘입니다. Attention 알고리즘은 주어진 토큰 벡터들을 하나의 벡터로 표현할 때 각 벡터들을 가중합하며, 각 가중치를 어떻게 주어야할 지 학습하는 알고리즘입니다. 이름에서 알 수 있듯, 어떤 토큰에 얼마나 주목해야하는 가(Attention)를 학습하는 알고리즘입니다. 가령 어떤 사용자가 상의 → 휴대폰 → 하의 를 보았고, 이 기록이 모델 Input으로 주어졌다고 합시다. 해당 사용자가 다음으로 휴대폰 케이스 를 보았고, 이를 맞추는 것이 모델의 목표로 주어졌다면, 모델은 상의 또는 하의 보다 휴대폰 에 더 많은 가중치를 주어야할 것입니다. 순차 데이터 모델은 이러한 Attention 알고리즘을 사용하여 사용자가 상호작용한 상품들의 패턴을 인식하고, 사용자의 문맥정보를 표현합니다.
이때 Attention 알고리즘에는 다양한 기법이 있지만, Google에서 공개한 Transformer 라는 알고리즘을 주로 사용합니다. Transformer 알고리즘은 BERT(Bidirectional Encoder Representations from Transformers)나 GPT(Generative Pretrained Transformer)와 같은 자연어처리 모델의 기반이 되었고, ChatGPT에 적용되어 성공적으로 상업화된 알고리즘입니다. 그리고 이러한 Transformer는 최근 추천 시스템에도 활발히 적용되고 있는 모델입니다.
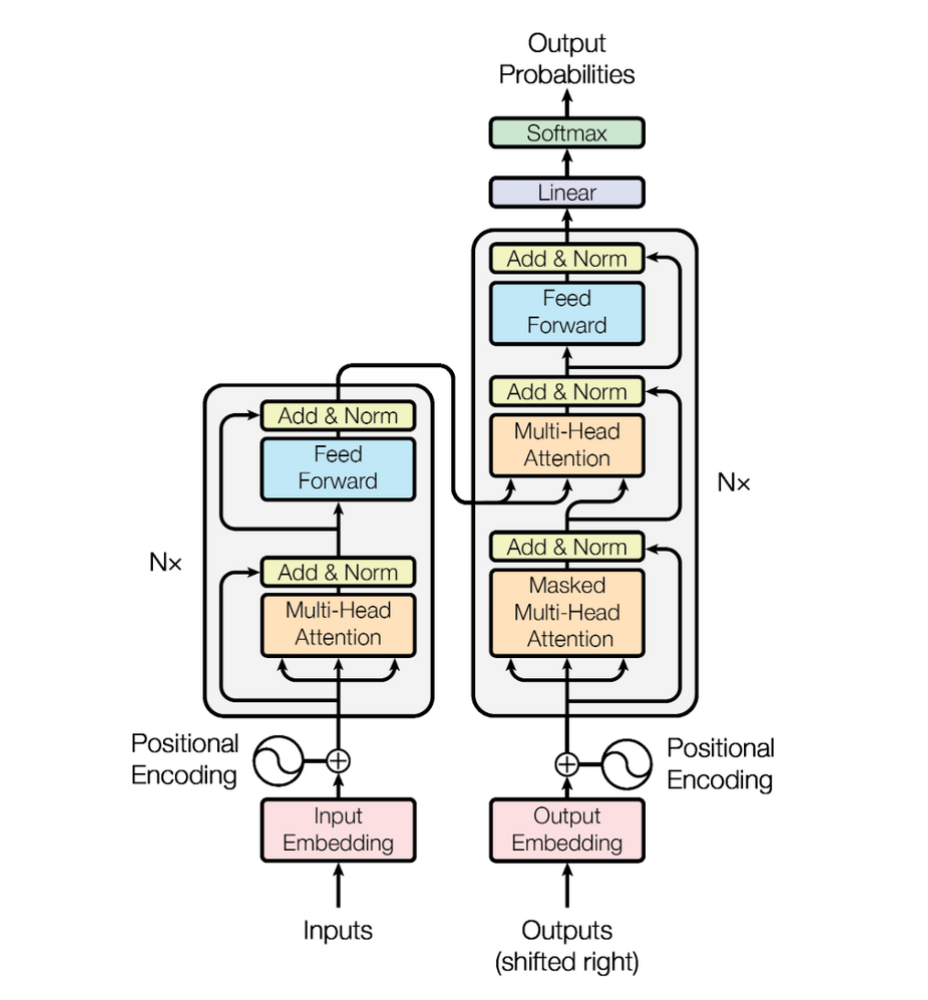
Transformer에 대한 내용은 다음 글에서 자세히 말씀드리도록 하겠습니다 🙂
Z.Ai의 엔지니어팀은 임베딩 기법과 순차 데이터 모델을 어떻게 더 잘 활용할 수 있을 지 고민하고 있습니다. 그리고 다양한 시도들을 진행하였습니다. 가령 임베딩 기법에 단편적인 상품 정보 뿐만 아니라 특정 상품과 함께 상호작용이 발생한 상품들의 정보도 해당 상품의 임베딩에 포함시키면 어떨까라는 생각이 들었고, 이를 위해 Z.Ai팀은 Graph Model을 차용하여 임베딩을 더 풍부하게 학습하는 방법을 시도하였습니다. 또한 사용자의 행동 정보 중 구매 혹은 좋아요와 같이 사용자의 선호를 명시적으로 파악할 수 있는 특정 이벤트를 더 잘 반영하기 위해 강화학습(Reinforcement Learning)을 통해 순차 데이터 모델을 더 발전시키기도 하였습니다.
앞으로의 글에서는 Z.Ai가 상품 특성 정보와 문맥적 정보를 더 잘 표현하기 위해 연구하고 있는 모델들에 대해 보다 자세한 내용을 다루고자 합니다. 다음 게시물에서는 오늘 잠시 언급되었던 Transformer 알고리즘에 대해 깊게 알아보는 시간을 가져보도록 하겠습니다.
다음 글도 많은 관심 부탁드려요! 😊

 자이의 개인화 추천으로 구매전환율 및 매출의 상승을 경험해 보세요!
자이의 개인화 추천으로 구매전환율 및 매출의 상승을 경험해 보세요!