

Kubernetes 환경에서 HPA와 Karpenter를 이용하여 Autoscaling 시스템 구축하기
들쑥날쑥한 트래픽, 어떻게 문제없이 처리할까?

안녕하세요. Z.Ai의 MLOps Engineer Shawn입니다.
저는 오늘 Kubernetes 환경에서 운영중인 어플리케이션에 트래픽이 갑자기 몰렸을 때 autoscaling을 가능케하는 방법에 대해 말씀드리려합니다.
거두절미하고 말씀드리면, 저희는 autoscaling을 하기 위해 HPA(Horizontal Pod Autoscaling)와 Karpenter를 함께 사용합니다. 각각이 무엇인지, 그리고 왜 이 둘의 조합을 사용하는지 예시 위주로 설명드리려고 합니다.
우선 어떤 상황에 autoscaling이 필요한지 생각해볼까요?
다음은 실제 저희의 어플리케이션 중 하나의 자원 사용량을 나타낸 그래프입니다. 가로축은 시간으로 총 24시간을 나타내고 있고, 세로축은 vCPU 사용량을 최저치를 기준으로 normalize하여 나타낸 것입니다.
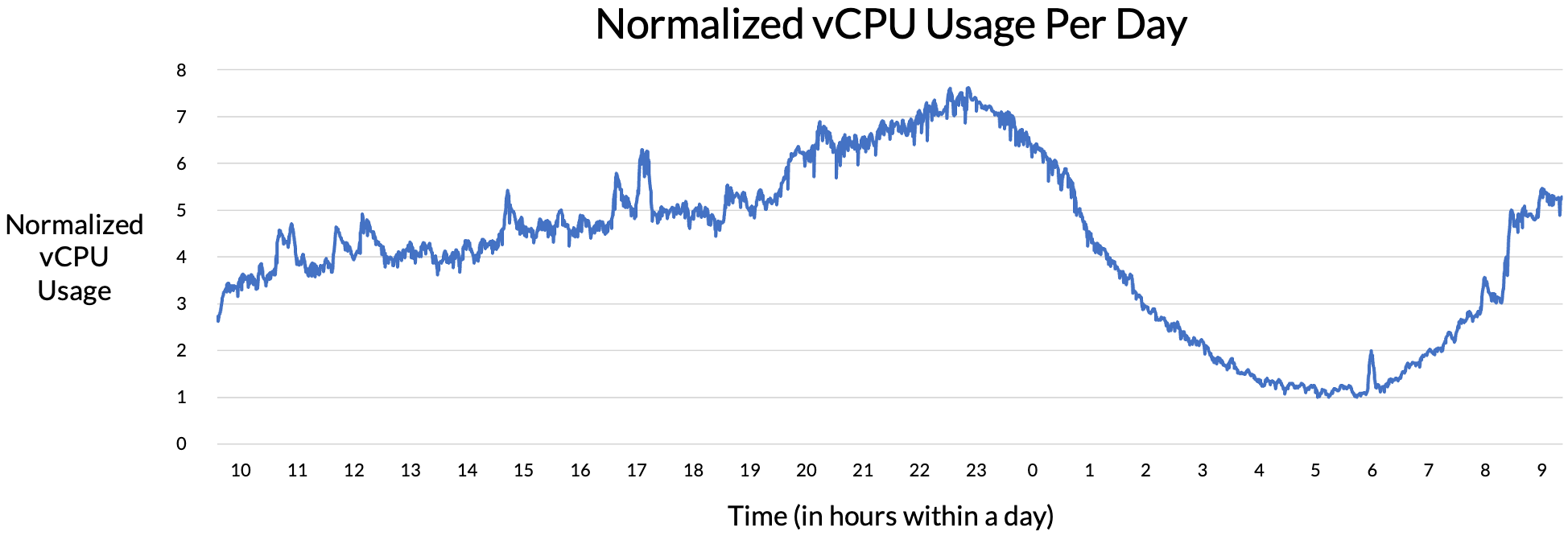
그래프를 보시면 사람들의 취침 시간인 오전 2시~8시에는 자원 사용량이 적고, 그 이후로는 점점 사용량이 늘다가 자정 이후로 다시 줄어드는 것을 확인하실 수 있습니다.
서버의 데이터 전송량을 트래픽이라고 하는데, 이처럼 트래픽은 일정하지 않고 여러가지 요인에 의해 영향을 받게 됩니다. 트래픽은 위 그래프에 나타난 것처럼 시간대에 따라 다른 양상을 보이기도 하고, 푸쉬 알림 등 특정 이벤트 발생 여부에 의해서도 영향을 받게 됩니다.
따라서 어플리케이션을 안정적으로 운영하기 위해서는, 1) 일정 수준의 트래픽을 평소에 무리 없이 처리할 수 있어야 하고, 2) 예상치 못하게 트래픽이 많아졌을 경우 이에 적절히 대응할 수 있어야합니다. 여기서 적절히 대응한다는 것은 사람의 개입 없이 자동으로 서버의 증설과 같은 액션이 일어나서, 트래픽이 몰리는 상황에서도 어플리케이션을 이용하는 사람 입장에서는 아무런 차이를 느끼지 않고 문제 없이 어플리케이션을 이용할 수 있게끔 보장해야한다는 것을 말합니다.
이렇게 일시적인 트래픽 증가 등에 대응하여 서버 자체의 capacity나 서버의 숫자를 자동으로 늘리는 행위를 autoscaling이라고 말합니다. 저희는 Kubernetes 환경에서 모든 어플리케이션을 운영하고 있기 때문에 컨테이너가 띄워진 Pod의 숫자 혹은 Pod 자체에 할당된 자원을 늘리는 것이 autoscaling의 방법이 될 수 있겠습니다.
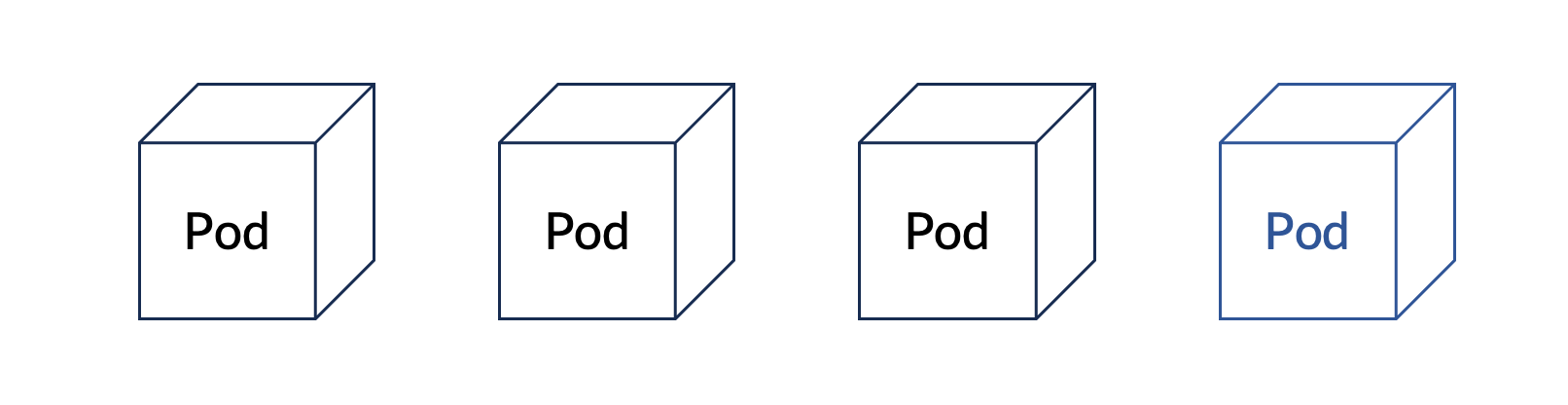
Pod autoscaling의 방법으로는 대표적으로 HPA(Horizontal Pod Autoscaling)와 VPA(Vertical Pod Autoscaling)가 있습니다. HPA은 아래 그림과 같이 수평적인 방향으로 Pod의 개수를 늘리는 방식으로 동작합니다.
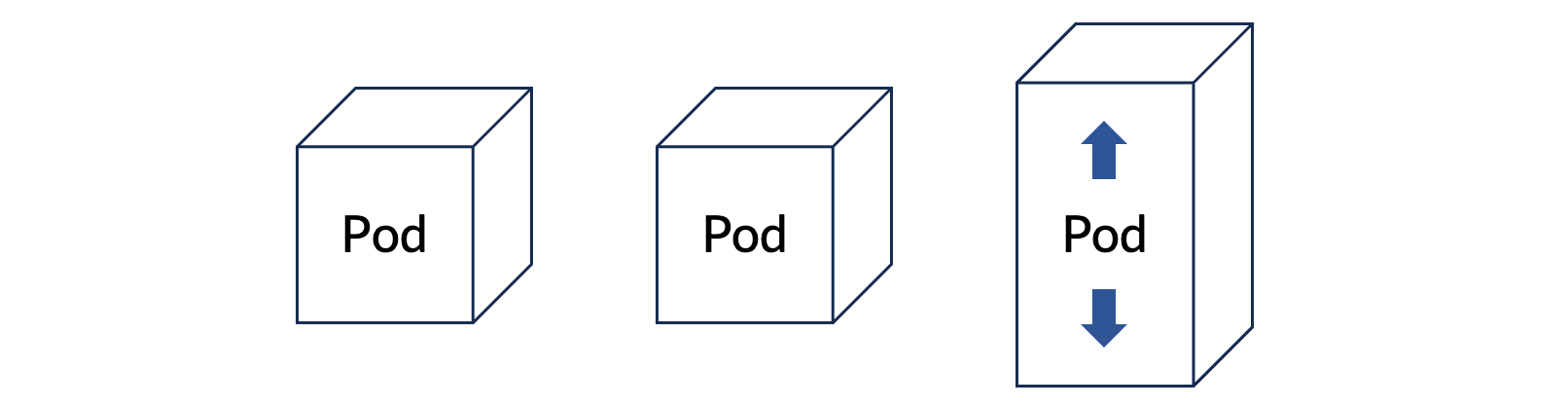
반대로 VPA은 아래 그림과 같이 수직적인 방향으로, Pod에 더 많은 자원을 할당하는 방식으로 동작합니다.
여기서 Pod autoscaling은 CPU나 memory를 기준으로 동작하는 것이 기본이나, 사용자가 정의한 custom 또는 external metric을 기준으로 동작하게끔 설정할 수도 있습니다. Pod autoscaling이 일어나는 상황과 기준에 대해서는 아래에서 좀 더 자세히 다루도록 하겠습니다. Kubernetes의 autoscaler GitHub repository를 보면 CPU나 memory를 기준으로 Pod autoscaling을 할 때 VPA와 HPA은 함께 사용되어서는 안된다고 명시되어 있습니다. 저희는 이 둘 중 HPA을 production 환경에서 사용하고 있는데 그 이유는 다음과 같습니다.
- Stateless 어플리케이션에 적합합니다. 저희는 microservice architecture를 표방하고, 이에 따라 모든 어플리케이션들이 상태를 저장하지 않기 (i.e., stateless) 때문에, 자원이 부족할 때 어플리케이션의 개수를 늘리기에 용이합니다. HPA은 어플리케이션을 호스팅하고 있는 Pod의 개수를 조절하는 방식으로 동작하기 때문에 이러한 stateless 어플리케이션에 적용하기에 적합합니다.
- Scalability 측면에서 유리합니다. 이론적으로 HPA은 VPA와 달리 upper limit이 없습니다. VPA은 아무리 Pod의 자원을 많이 늘리고 싶어도 해당 Pod가 running하고 있는 node의 자원보다 더 늘릴 수는 없습니다. 하지만 HPA은 자원 부족, 배포할 수 있는 Pod의 개수 초과 등의 이유로 해당 node에 Pod를 더 띄울 수 없으면 다른 node를 찾아 여기에 Pod를 더 띄울 수가 있습니다. 이러한 점은 cluster 전체의 관점에서 봤을 때 자원을 더욱 효율적으로 사용하게 된다는 장점으로도 작용합니다.
- 구현이 용이합니다. 일반적으로 VPA을 적용할 때는 HPA을 적용할 때보다 어플리케이션의 자원 사용 패턴에 대해 더욱 잘 파악하고 있어야 하고, 필요에 따라 자원 사용량을 fine-tuning 해야 할 수도 있습니다. HPA은 VPA보다 상대적으로 적용하기가 용이합니다.
HPA은 Pod가 사용하고 있는 자원이 일정 threshold 이상이면 그 개수를 늘려 트래픽을 분산시키고, 다시 그만큼의 Pod가 필요 없어지면 개수를 줄입니다. 이런 방식으로 동작하기 위해서는 Pod가 사용하고 있는 자원의 양을 알아야 하는데, 여기에서 Kubernetes Metrics Server라는 것이 활용됩니다. Kubernetes Metrics Server는 cluster 전반에 걸쳐 자원의 사용량 정보를 수집하는 역할을 합니다. AWS에서는 HPA를 사용하기 위한 prerequisites로 1) Kubernetes cluster, 2) Kubernetes Metrics Server, 그리고 3) kubectl client를 듭니다.
HPA은 Kubernetes API와 controller의 형태로 구현되어 있는데, Kuberntes control plane에서 돌고 있는 HPA controller가 주기적으로 target(Deployment 등)의 자원 사용량을 체크하는 핵심적인 역할을 수행하게 됩니다. 보다 구체적인 동작 원리는 이 링크에서 확인하실 수 있습니다.
그럼 예시를 통해 HPA가 어떻게 동작하는지 살펴보겠습니다.
다음 YAML 파일을 통해 어플리케이션을 배포한다고 가정하겠습니다. 파일은 간결성을 위해 필요한 부분만 남겼고, Deployment와 HorizontalPodAutoscaler만 나타냈습니다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: zai-sample-api
labels:
app: zai-sample-api
spec:
replicas: 1
selector:
matchLabels:
app: zai-sample-api
template:
metadata:
labels:
app: zai-sample-api
spec:
containers:
- name: zai-sample-api-base
image: ${ZAI_AWS_ACCOUNT_ID}.dkr.ecr.ap-northeast-2.amazonaws.com/zai-sample-api:0.0.1
ports:
- containerPort: ${ZAI_SAMPLE_API_PORT}
resources:
requests:
memory: 2Gi
cpu: 1000m
limits:
memory: 4Gi
cpu: 2000m
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: zai-sample-api
spec:
minReplicas: 1
maxReplicas: 10
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: zai-sample-api
metrics:
- type: resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 150
- type: resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 100
위 예시에서는 zai-sample-api라는 Deployment를 정의하고 있는데 눈여겨 볼 부분은 spec.template.spec.containers의 resources입니다. 해당 어플리케이션은 2GiB의 memory와 1 vCPU를 요청하고 있고, 최대 4GiB의 memory와 2 vCPUs를 쓸 수 있음을 정의하고 있습니다. HorizontalPodAutoscaler가 정의된 부분을 보면 memory, vCPU가 각각 150%, 100% 사용됐을 때를 기준으로 HPA가 동작하게끔 되어 있습니다. 여기서 퍼센트는 resources.requests를 기준으로 적용됩니다. 다시 말하면, memory가 2GiB의 150%인 3GiB 이상 쓰일 때, 그리고 vCPU가 1000m의 100%인 1000m 이상 쓰일 때 HPA가 더 많은 Pod를 띄우도록 trigger 된다는 것입니다.
최초로 위 파일에 정의된대로 Kubernetes 환경에 배포하였을 때 kubectl get hpa 명령어를 치면 아래와 같이 나옵니다.
shawn@desktop:~$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
zai-sample-api Deployment/zai-sample-api 39%/150%, 1%/100% 1 10 1 2h
여기서 저희는 자체적으로 제작한 load testing tool을 이용해 고의적으로 해당 어플리케이션에 많은 요청을 보내보았습니다. 일정 시간동안 부하를 주었을 때 다시 kubectl get hpa 명령어를 치면 아래와 같이 vCPU 사용량이 늘었음을 알 수 있습니다. (TARGETS에서 전자가 memory, 후자가 vCPU를 의미합니다.)
shawn@desktop:~$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
zai-sample-api Deployment/zai-sample-api 47%/150%, 166%/100% 1 10 2 2h
shawn@desktop:~$ kubectl get deployment zai-sample-api
NAME READY UP-TO-DATE AVAILABLE AGE
zai-sample-api 1/1 2 2 2h
vCPU 사용량이 166%로 미리 지정한 100%를 넘었기 때문에 HPA이 작동되었고, 그 결과 기존 1개의 Pod보다 하나 더 많은 총 2개의 Pod가 생성되었습니다. Load testing을 끝내고 조금 기다리면, 아래와 같이 Pod의 개수가 다시 1개로 줄어든 것을 확인할 수 있습니다.
shawn@desktop:~$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
zai-sample-api Deployment/zai-sample-api 38%/150%, 2%/100% 1 10 1 3h지금까지 예시와 설명을 통해 저희가 미리 설정해둔 threshold 이상의 자원이 사용되면 HPA이 작동하여 자원의 utilization rate이 threshold 이하로 떨어질 수 있게끔 더 많은 Pod를 생성한다는 것을 알 수 있었습니다. 그러나 현 상황에서는 Pod를 무한정 많이 생성할 수는 없을겁니다. 일단 당연히 node의 자원 한도 내에서만 Pod를 생성할 수 있을 것이고, node 별로 띄울 수 있는 Pod의 개수에 제한(i.e., max Pods per node)도 있습니다. 예를 들어 AWS의 m5.2xlarge instace는 8 vCPUs, 32GiB memory의 자원 한도가 정해져있고, 여기에 최대 58개의 Pod를 띄울 수 있습니다.
만약 cluster를 구성하고 있는 모든 node에 할 수 있는 한도 내에서 Pod를 빽빽히 생성하고나서도 여전히 트래픽이 감당하기 힘들 정도로 들어오고 있다면 어떻게 해야 할까요? 이때 저희가 택한 방법이 바로 Karpenter를 이용한 자동화된 node provisioning입니다. (Karpenter에서는 autoscaling을 통해 node를 추가로 공급하는 것을 node를 provision한다고 말합니다.) Karpenter는 Kubernetes 환경에서 사용하기 위한 오픈 소스의 node provisioning 프로젝트로, 최초에 AWS에서 활용되기 위해 만들어졌지만, 현재는 cloud-agnostic하기 때문에 다른 cloud provider의 어플리케이션에서도 사용할 수 있습니다.
제가 사용해보면서 느낀 Karpenter의 장점을 몇 가지 나열하자면 아래와 같습니다.
- 굉장히 빠릅니다. Karpenter가 새로운 node를 provision해야겠다고 판단하는 순간부터 실제 provisioning이 이루어지기까지 수십 초~수 분밖에 걸리지 않습니다. 네트워크 연결 등 실제 node의 활용이 가능하기까지 필요한 시간이 그렇습니다. 일반적인 cloud 환경에서 직접 node를 추가하더라도 꽤 시간이 걸린다는 것을 생각했을 때 놀라울만큼 빠른 속도입니다.
- 비용 측면에서 효율적입니다. Karpenter는 provisioning을 할 때 사용자가 미리 정의해놓은 instance type의 pool을 보고 이 중에서 부족한 자원(즉, request한 자원)을 serve할 수 있는 instance 중 가장 저렴한 것을 알아서 찾아서 provision합니다. 뿐만 아니라 해당 node의 사용이 끝났으면 사용자의 설정에 따라 일정 시간이 지난 후에 바로 deprovisioning해서 불필요한 비용이 드는 것을 막아줍니다.
- 설치와 운영이 쉽습니다. Karpenter의 설치는 공식 document를 따라하면 쉽게 할 수 있고, 운영에 있어서도 크게 신경 쓸 것이 없습니다. Karpenter의 가장 큰 장점은 node를 늘릴 것인지 줄일 것인지 판단하는 것에서부터 실제로 node를 늘렸다가 줄이는 것까지 알아서한다는 것입니다. Cluster 전반에 걸쳐 합리적인 자원 request 및 limit을 설정해두고, Karpenter provisioner를 초기에 잘 정의해서 배포해둔다면 그 이후로는 사용자가 신경 쓸 일이 없습니다.
Karpenter를 활용할 수 있도록 다음과 같은 YAML 파일을 통해 Provisioner 등을 정의했습니다. AWS의 EC2 instance를 사용한다고 가정하였고, 주석을 통해 세부 요소를 설명하였습니다.
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: sample
spec:
providerRef:
name: sample
# Karpenter로 provision된 모든 node에 적용될 label입니다.
labels:
type: karpenter
# Karpenter로 provision된 모든 node에 적용될 annotation입니다.
annotations:
maintainer: "zai"
# Provision할 node에 대한 requirements입니다.
requirements:
- key: "node.kubernetes.io/instance-type"
operator: In
values: ["m5.large", "m5.xlarge", "r5.large", "r5.xlarge"]
- key: "kubernetes.io/arch"
operator: In
values: ["amd64"]
- key: "kubernetes.io/os"
operator: In
values: ["linux"]
- key: "karpenter.sh/capacity-type"
operator: In
values: ["on-demand"]
# 해당 Provisioner가 provision 할 수 있는 모든 node의 자원의 limit입니다.
limits:
resources:
cpu: "256"
memory: 1Ti
# consolidation.enabled를 true로 설정하면 Karpenter가 더 이상 필요없는 node를 deprovision합니다.
# Deprovision하기가 불가능하면 더 낮은 비용의 node로 변경하려는 시도를 합니다.
# consolidation:
# enabled: true
# Node가 더 이상 사용되지 않을 때 정의된 시간이 지난 후에 deprovision됩니다.
# consolidation.enabled가 true라면 이 설정을 함께 사용할 수 없습니다.
ttlSecondsAfterEmpty: 30
# 동시에 여러 Provisioner가 적용 가능할 때 우선 순위로 작용할 상수입니다.
# 높은 weight이 더 높은 우선 순위를 의미합니다.
# weight: 10
---
apiVersion: karpenter.k8s.aws/v1alpha1
kind: AWSNodeTemplate
metadata:
name: sample
spec:
subnetSelector: # 필수로 작성되어야 하며 해당 태그가 설정된 Subnet을 찾습니다.
karpenter.sh/discovery: zai-cluster
securityGroupSelector: # 필수로 작성되어야 하며 해당 태그가 설정된 Security Group을 찾습니다.
karpenter.sh/discovery: zai-cluster
# amiFamily: AL2 # 선택적으로 작성될 수 있습니다.
# blockDeviceMappings: # 선택적으로 작성될 수 있으며 storage device에 대한 정보입니다.
# - deviceName: /dev/xvda
# ebs:
# volumeSize: 10Gi
# volumeType: gp2
# iops: 3000
# deleteOnTermination: true
# throughput: 125지금까지 autoscaling을 위한 방법으로 실제로 저희가 활용하고 있는 HPA와 Karpenter에 대해 설명드렸습니다. Production 환경에서 일반적으로 많이 활용되는 practice로 소개해드렸지만, 상황에 따라 HPA보다는 VPA를 활용하는 것이 나을 수도 있고, Karpenter 대신 Cluster Autoscaler 등 다른 node provisioner를 활용하는 것이 나을 수도 있습니다. 각자 사용하시는 Kubernetes cluster 환경과 어플리케이션의 특성을 고려해야하지만, 운영자 입장에서 좀 더 편안하게, 그리고 안전하게 들쑥날쑥한 트래픽을 문제없이 처리하기 위해서는 autoscaling을 위한 시스템 구축이 필수적이라고 생각합니다.
저희처럼 HPA와 Karpenter을 함께 활용하는 것을 고민하고 계시다면 이 글이 도움이 됐으면 좋겠습니다.
감사합니다.
[참고 문헌]
- https://docs.aws.amazon.com/eks/latest/userguide/horizontal-pod-autoscaler.html
- https://github.com/kubernetes/autoscaler/
- https://github.com/kubernetes-sigs/metrics-server/
- https://karpenter.sh/docs/
- https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/

 자이의 개인화 추천으로 구매전환율 및 매출의 상승을 경험해 보세요!
자이의 개인화 추천으로 구매전환율 및 매출의 상승을 경험해 보세요!